Employee Attrition Factors Prediction
Introduction
With trends like the Great Resignation causing companies to lose numerous valuable employees, it is critical now, more than ever, to understand the reasons why. Luckily, project directors Maliha Lodi and Afnan Rahman, along with their team, have developed a machine learning and data analytics-based approach for determining factors behind employee attrition. Their system identifies areas of improvements across all departments of a company, with the hope of providing insights to Human Resources teams on how to improve employee retention rate by making the necessary improvements. To this day, no automated process exists to predict employee attrition. As such, companies suffer large amounts of tangible and intangible losses due to high employee turnover rates. As such, vital for companies to understand how to retain their top talent. By utilizing an approach like this, companies can use the results from these models to understand their employees better and mitigate turnover and attrition.
Framework
Dataset The data used for this project is from the IBM HR Analytics Employee Attrition & Performance Dataset. It contains 35 categorical and numerical features for 1470 unique employees who work in one of nine different job roles, along with the information on whether they have quit or not. As the project largely depends on the predictions done by supervised learning, the labels in the dataset are crucial for this project.
Preprocessing The dataset contained many categorical variables, which were transformed into numerical data using one-hot encoding. As the dataset was also imbalanced, Synthetic Minority Oversampling Technique (SMOTE) was used to fix this problem by artificially growing the number of employees who quit. The final preprocessing step taken included removing irrelevant variables, such as employee number, and aggregating common variables like daily_rate, hourly_rate, and monthly_rate into one column.
Architecture
Classifiers
The project begins by using five binary classifiers that classify employees based on whether they would quit their job or not. The models are Logistic Regression, Decision Tree, Random Forest, XGBoost, and Support Vector Machine (SVM). These models were chosen since past research has used them to address similar classification problems.
Clustering
Through clustering, common trends were identified within certain groups of employees, namely what distinct “clusters” of employees will quit their jobs. K-means clustering was used as the primary algorithm, while t-SNE (t-distributed Stochastic Neighbour Embedding) was used to reduce the number of features. t-SNE was able to capture similarities among data points and reduce computation costs for K-Means, which is used to group the employees predicted to quit.
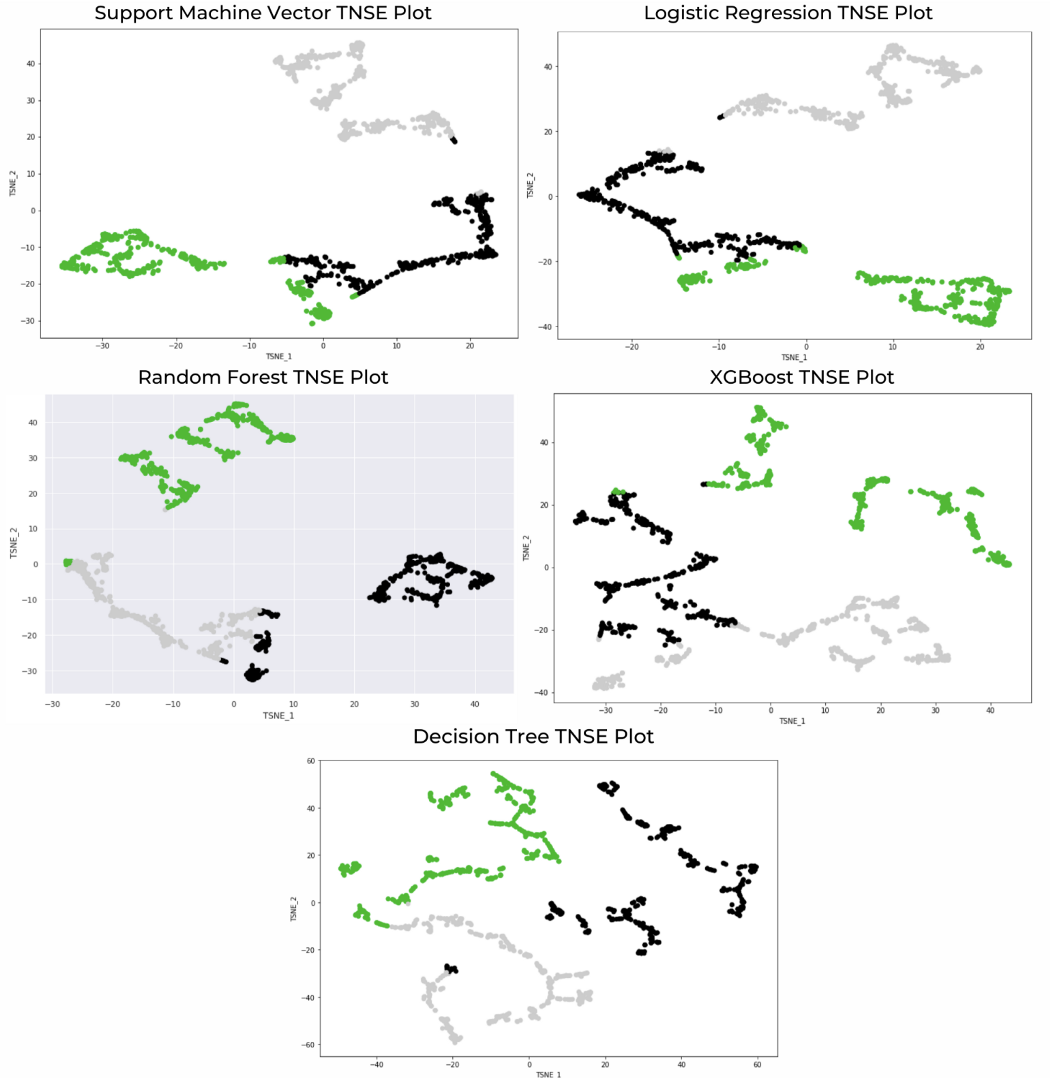
Results
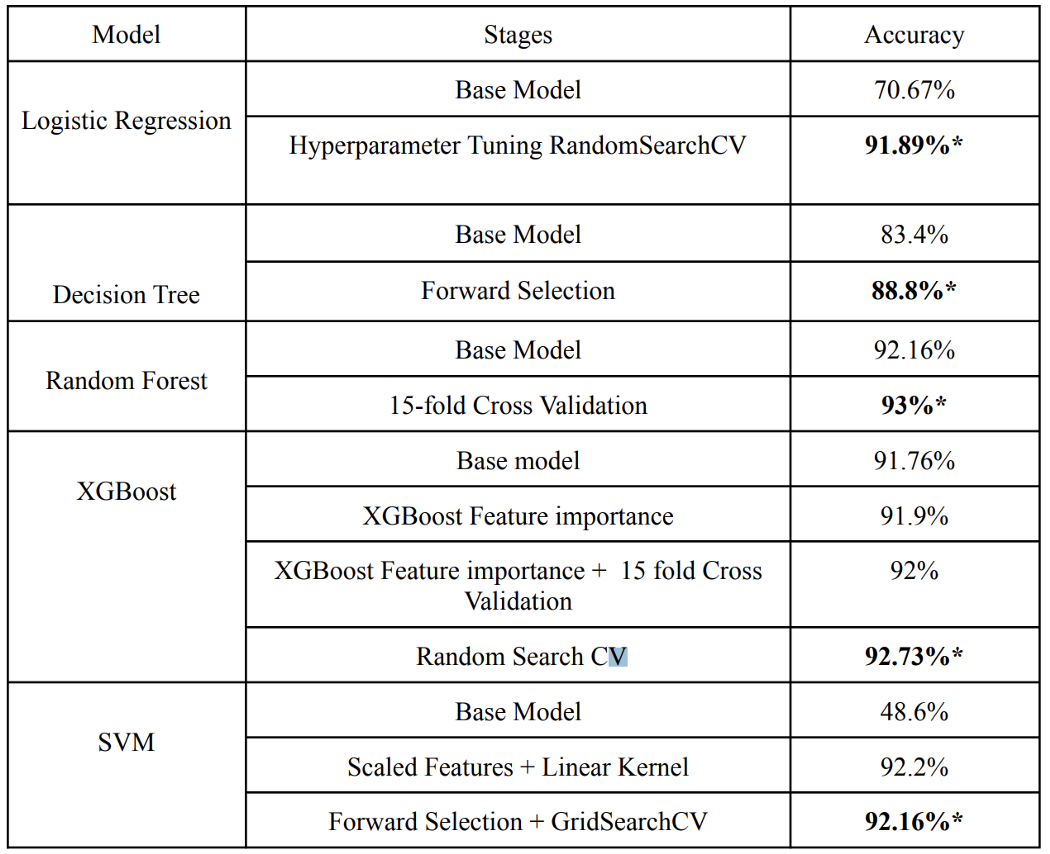
For more detailed analysis of different groups, please visit our Medium Article.
Future Works
Large corporations and small businesses can utilize the models’ results to understand their employees better, thus mitigating employee turnover. Companies can pass their employee data through the trained models, find common factors between employees projected to leave, and then make the necessary changes to ensure a lower employee turnover rate. In the future, it may be interesting to experiment with more advanced machine learning models, such as a neural network, to see whether such a model’s predictions are more accurate than the traditional machine learning models used in this study
